# Voicebox:开源本地声音克隆神器,ElevenLabs的免费替代者
声音,是人类最自然的交互方式。但在AI语音领域,长期以来存在一个两难困境:云端服务(如ElevenLabs)效果出色但价格不菲、数据上传存在隐私风险;本地方案又往往效果粗糙、门槛极高。
**Voicebox** 的出现打破了这个僵局——它是一个完全本地运行的开源语音克隆工作室,被越来越多的创作者称为”免费版ElevenLabs”。只需几秒音频样本,就能克隆任意声音;支持23种语言;不联网、不传数据、不限次数。
## Voicebox 是什么?
Voicebox 是由开发者 Jamie Pine 发起的开源项目,目前在GitHub上已获得 **18000+ Star**,是2026年增速最快的AI开源项目之一。
它的定位非常明确:**本地优先的AI语音工作室**——将语音克隆(Voice Cloning)、文本转语音(TTS)、语音听写(Dictation)、多轨音频编辑、后期处理等专业级语音工作流,全部集成到一个桌面应用中,且所有数据都在你的机器上运行。
用一句话概括:**ElevenLabs + WisprFlow 的开源本地替代品。**
## 核心功能一览
### 1. 零样本声音克隆
这是Voicebox最核心的能力。你只需要提供 **几秒钟的参考音频**,Voicebox就能克隆出该说话人的声音特征,然后用这个声音朗读任意文本。
这意味着:
– 🎙️ 无需录制大量语料,一段5秒的语音即可
– 🔒 声纹数据不上传,始终留在本地
– 🎭 克隆后的声音可用于TTS生成、角色配音等场景
### 2. 七大TTS引擎
Voicebox 集成了7种主流开源TTS引擎,每种引擎各有特长:
| 引擎 | 特点 |
|——|——|
| **Qwen3-TTS** | 阿里通义千问出品,中文效果最佳 |
| **Qwen CustomVoice** | 千问定制声音版,支持50+预设音色 |
| **LuxTTS** | 轻量高性能,适合快速生成 |
| **Chatterbox Multilingual** | 多语言支持,23种语言覆盖 |
| **Chatterbox Turbo** | 极速生成,支持情感标签如[laugh][sigh] |
| **HumeAI TADA** | 情感表达丰富,适合角色配音 |
| **Kokoro 82M** | 超小模型,低配设备也能跑 |
### 3. 23种语言支持
从中文、英语、日语到阿拉伯语、印地语、斯瓦希里语,Voicebox 覆盖了全球23种主要语言。对于中文用户来说,**Qwen3-TTS引擎的中文效果尤为出色**,发音自然、节奏流畅。
### 4. 多轨时间线编辑器
这是Voicebox区别于其他TTS工具的杀手级功能。它内置了一个 **DAW风格的多轨时间线编辑器**,你可以:
– 🎵 在同一项目中混合多个声音角色
– ✂️ 对每条音频片段进行裁剪、拖拽、拼接
– 🎚️ 调整音量、添加淡入淡出
– 📻 创作有声书、播客、广播剧等多人对话场景
不再是生成一段段孤立的音频再手动拼接——Voicebox让语音创作像剪辑视频一样流畅。
### 5. 后期处理效果
内置专业级音频后期处理:
– 🎸 **Pitch Shift** — 变调
– 🏔️ **Reverb** — 混响
– ⏱️ **Delay** — 延迟
– 🎶 **Chorus** — 合唱
– 🔊 **Compression** — 压缩
– 🎛️ **Filters** — 滤波
无需额外使用Audacity等工具,一条龙搞定。
### 6. 全局语音听写
Voicebox 还支持语音输入(类似WisprFlow)。设置全局快捷键后,在任何应用中按快捷键,说话内容就会被实时转写并输入到当前文本框中。
### 7. MCP服务器——给AI Agent一个声音
Voicebox 内置了 **MCP(Model Context Protocol)服务器**,这意味着任何支持MCP的AI代理(如Claude、Cursor等)都可以调用Voicebox生成语音。你可以让AI助手用你克隆的声音”说话”——这为语音驱动的AI应用打开了无限可能。
## 与云端服务对比
| 特性 | Voicebox | ElevenLabs | WisprFlow |
|——|———-|————|———–|
| 数据位置 | 本地 | 云端 | 云端 |
| 声音克隆 | ✅ 零样本 | ✅ 零样本 | ❌ |
| TTS生成 | ✅ 7种引擎 | ✅ 自研模型 | ❌ |
| 语音听写 | ✅ 全局热键 | ❌ | ✅ |
| 使用费用 | 🆓 免费 | 💰 订阅制 | 💰 订阅制 |
| 调用次数 | ♾️ 不限 | 📊 按额度 | 📊 按额度 |
| 隐私保护 | ✅ 完全本地 | ⚠️ 上传数据 | ⚠️ 上传数据 |
| 多轨编辑 | ✅ 内置 | ❌ | ❌ |
| MCP集成 | ✅ 内置 | ❌ | ❌ |
| 离线使用 | ✅ 完全 | ❌ | ❌ |
## 硬件需求

Voicebox 对硬件的要求并不苛刻:
– **最低配置**:8GB内存,无独显也能运行(使用CPU推理,速度较慢)
– **推荐配置**:16GB+内存,NVIDIA显卡(6GB+显存),CUDA加速后生成速度飞快
– **存储空间**:约2-5GB(取决于下载的模型数量)
– **操作系统**:Windows / macOS / Linux 全平台支持
## 快速上手
### 方式一:安装包(推荐新手)
1. 访问 [voicebox.sh](https://voicebox.sh) 或 [GitHub Releases](https://github.com/jamiepine/voicebox/releases)
2. 下载对应平台的安装包(Windows: `.exe` / macOS: `.dmg` / Linux: `.AppImage`)
3. 双击安装,首次启动会自动下载所需模型
4. 输入文本,选择引擎,点击生成——就这么简单
### 方式二:源码运行(适合开发者)
“`bash
git clone https://github.com/jamiepine/voicebox.git
cd voicebox
just setup # 创建虚拟环境,安装依赖
just dev # 启动后端 + 桌面应用
“`
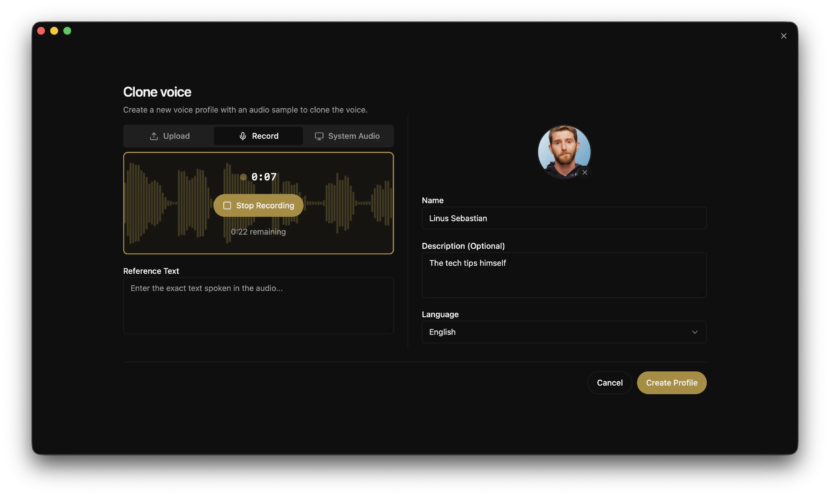
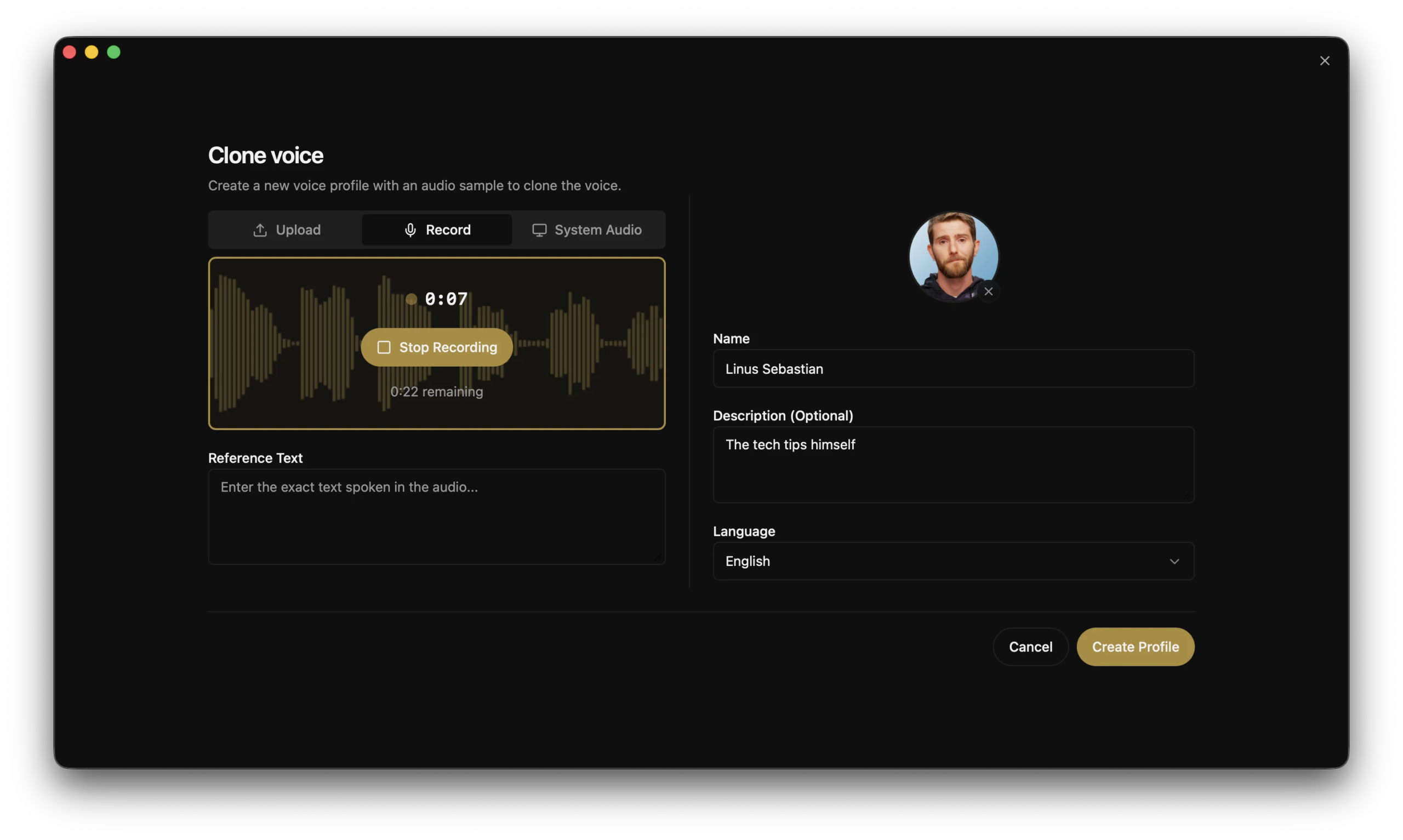
### 声音克隆步骤
1. 录制或导入一段参考音频(3-10秒即可)
2. 在Voicebox中创建新的声音配置文件
3. 上传参考音频作为声音样本
4. 输入想要生成的文本
5. 选择TTS引擎和声音配置
6. 点击生成,几秒钟即可获得克隆语音
## 典型应用场景
**📚 有声书与播客制作** — 用多轨编辑器创作多人对话内容,一个人生成整个剧组的配音
**🎬 短视频配音** — 克隆自己的声音,批量生成解说词,无需反复录音
**♿ 无障碍辅助** — 为视障用户提供语音朗读,为失声用户提供声音恢复
**🎮 游戏角色配音** — 独立开发者无需请配音演员,自己克隆不同角色声音
**🤖 AI语音助手** — 通过MCP给AI Agent配置自定义声音,打造个性化的语音交互体验
**🌍 多语言内容本地化** — 用同一个声音模型生成不同语言的语音,保持品牌声音一致性
## 隐私与伦理

声音克隆技术强大,但也带来了伦理挑战。Voicebox 团队对此非常重视:
– 所有数据和模型都在本地运行,**声纹信息不会泄露到互联网**
– 不提供云端API服务,从架构层面杜绝了大规模滥用的可能
– 项目遵循负责任的开源协议,明确禁止用于欺诈、冒充等非法用途
作为使用者,我们也应当遵守基本伦理准则:**只克隆自己或获得授权的声音,不用于欺骗或冒充他人。**
## 写在最后
Voicebox 的出现,标志着语音克隆技术从”高门槛专业工具”走向”人人可用的桌面应用”。它用开源和本地化的方式,让每个人都能拥有专业级的语音创作能力——不需要订阅,不需要上传数据,不需要担心次数限制。
在AI语音赛道上,云端服务固然便捷,但隐私和成本始终是绕不过的门槛。Voicebox 用一种更自由的姿态,给出了不同的答案:**你的声音,你的数据,你的选择。**
> 项目地址:[github.com/jamiepine/voicebox](https://github.com/jamiepine/voicebox)
> 官方网站:[voicebox.sh](https://voicebox.sh)
—
*本文由万观科技编辑整理,更多科技资讯请关注[老周博客](https://www.zhoujianhui.com)与[万观科技官网](https://www.wanguantech.com)。*

