相关文件下载地址:
https://www.zhoujianhui.com/upload/apm-server-7.4.2-x86_64.rpm
https://www.zhoujianhui.com/upload/elasticsearch-7.4.2-x86_64.rpm
https://www.zhoujianhui.com/upload/kafka-manager-2.0.0.2.zip
https://www.zhoujianhui.com/upload/kafka-manager-master.zip
https://www.zhoujianhui.com/upload/kibana-7.4.2-x86_64.rpm
虚机系统:CentOS7.7
升级所有包,改变软件设置和系统设置,系统版本内核都升级
#yum -y update
关闭firewall:
systemctl disable firewalld.service #禁止firewall开机启动
systemctl stop firewalld.service #停止firewall
关闭selinux 查看状态:sestatus
vim /etc/selinux/config
SELINUX=disabled
reboot
需要开放的端口
|
服务
|
需要开放的端口
|
|
Elasticsearch
|
tcp/9200和9300
|
|
kibana
|
tcp/5601
|
|
logstash
|
tcp/5000
|
ELK stack有四个主要组成部分:
Logstash:处理输入日志服务器组件
Elasticsearch:存储所有的日志
Kibana:搜索和显示日志的Web界面,将通过nginx代理
filebeat:安装在客户端的服务器上,将日志发送到LogStash,filebeat作为日志传送代理,利用网络协议与LogStash沟通
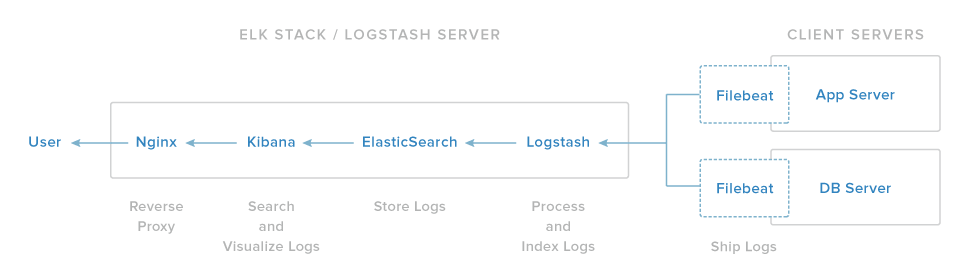
将前3个安装在一台服务器上,称为:ELK Server,filebeat安装在所有的客户端服务器,收集日志,称为:Client Servers
卸载旧版 jdk1.7
rpm -qa|grep java
卸载
rpm -e –nodeps XXXXXXX
安装 Java 8
yum install -y java-1.8.0-openjdk java-1.8.0-openjdk-devel
yum -y install java-openjdk-devel java-openjdk
一、安装 Elasticsearch
1、手动安装:
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-x86_64.rpm
校验值为:wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-x86_64.rpm.sha512
yum install -y perl-Digest-SHA
shasum -a 512 -c elasticsearch-7.4.2-x86_64.rpm.sha512
rpm –install elasticsearch-7.4.2-x86_64.rpm
将服务加入开机启动:
sudo /bin/systemctl daemon-reload
sudo /bin/systemctl enable elasticsearch.service
启动和停止服务:
sudo systemctl start elasticsearch.service
sudo systemctl stop elasticsearch.service
sudo systemctl status elasticsearch.service
安装路径:/etc/elasticsearch
日志路径:/var/log/elasticsearch/
测试:curl -X GET “localhost:9200”
2、修改elasticsearch配置文件:
一共有2个文件,elasticsearch.yml和log4j2.properties,路径在/etc/elasticsearch/
vim /etc/elasticsearch/elasticsearch.yml
path.data: /var/lib/elasticsearch path.logs: /var/log/elasticsearch
#node.name: ${HOSTNAME} #network.host: ${ES_NETWORK_HOST}
network.host:localhost
二、安装Kibana
1、手动安装:
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-x86_64.rpm shasum -a 512 kibana-7.4.2-x86_64.rpm
【校验值为:https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-x86_64.rpm.sha512】
rpm –install kibana-7.4.2-x86_64.rpm
将服务加入开机启动:
/bin/systemctl daemon-reload /bin/systemctl enable kibana.service
启动和停止服务:
systemctl start kibana.service systemctl restart kibana.service
2、修改Kibana配置文件:
vim /etc/kibana/kibana.yml
可进行相关参数的修改,由于安装在本地,这里默认可不做修改
server.host: “localhost”
改为:
server.host: “0.0.0.0”
3、汉化
vim /etc/kibana/kibana.yml
i18n.locale: “zh-CN”
systemctl restart kibana
三、安装Nginx (可选,添加kibana身份验证)
1、添加 EPEL REPOSITORY
yum -y install epel-release
2、安装Nginx
yum -y install nginx
3、安装httpd-tools,生成Kibana的用户名和密码
sudo yum -y install httpd-tools
4、创建管理员用户名和密码
使用htpasswd创建一个管理员用户,被称为“kibanaadmin”(自定义),那就需要访问Kibana Web界面:
htpasswd -c /etc/nginx/htpasswd.users kibanaadmin (admin)
提示输入密码,kibanaadmin (admin)记住这个密码,登陆kibana的web界面
5、配置nginx服务Kibana
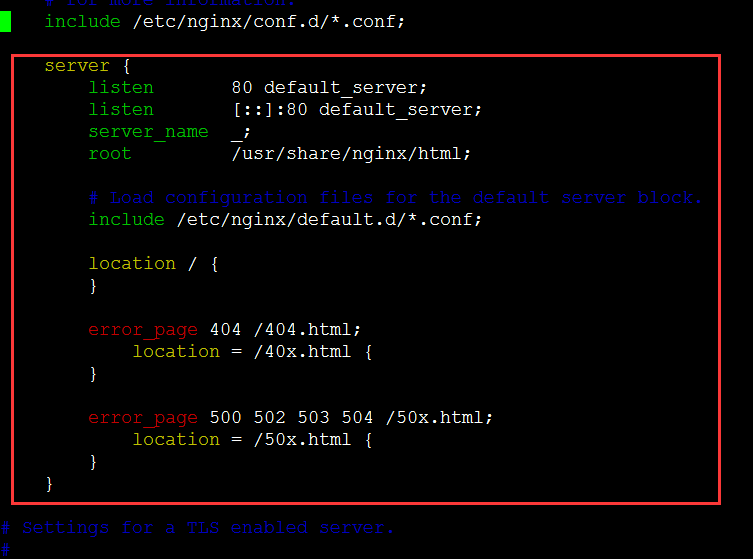
vim /etc/nginx/nginx.conf
注释server{ } 所有内容
保留
include /etc/nginx/conf.d/*.conf;
 、
、 
创建一个kibana.conf配置文件
sudo vim /etc/nginx/conf.d/kibana.conf
server {
listen 80;
server_name 172.16.72.72;
auth_basic “Restricted Access”;
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://172.16.72.72:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection ‘upgrade’;
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
启动Nginx并加入自启动
sudo systemctl start nginx
sudo systemctl enable nginx
测试访问:
四、安装Logstash
1、手动安装
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.rpm
【校验值为:https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.rpm.sha1】
sha1sum logstash-7.4.2.rpm
rpm –install logstash-7.4.2.rpm
将服务加入开机启动:
systemctl daemon-reload
/bin/systemctl enable logstash.service
启动服务
systemctl start logstash.service
2、配置Logstash
vim /etc/logstash/conf.d/logstash.conf
input { stdin { } } output { elasticsearch { hosts => [“localhost:9200”] } stdout { codec => rubydebug } }
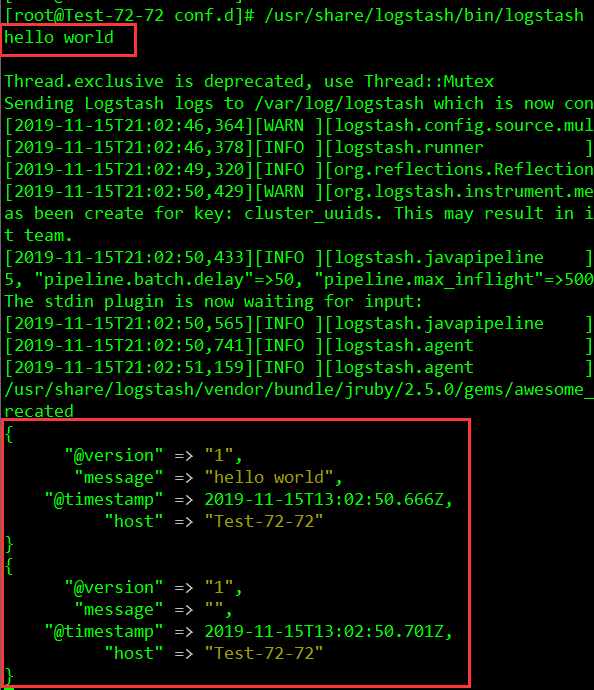
测试:
/usr/share/logstash/bin/logstash -e ‘input { stdin { } } output { stdout {} }’ –path.settings /etc/logstash
输入:hello world
创建一个kibana.conf配置文件
sudo vim /etc/nginx/conf.d/kibana.conf
server {
listen 80;
server_name 172.16.72.72;
auth_basic “Restricted Access”;
auth_basic_user_file /etc/nginx/htpasswd.users;
location / {
proxy_pass http://172.16.72.72:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection ‘upgrade’;
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}
启动Nginx并加入自启动
sudo systemctl start nginx
sudo systemctl enable nginx
测试访问:
四、安装Logstash
1、手动安装
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.rpm
【校验值为:https://artifacts.elastic.co/downloads/logstash/logstash-7.4.2.rpm.sha1】
sha1sum logstash-7.4.2.rpm
rpm –install logstash-7.4.2.rpm
将服务加入开机启动:
systemctl daemon-reload
/bin/systemctl enable logstash.service
启动服务
systemctl start logstash.service
2、配置Logstash
vim /etc/logstash/conf.d/logstash.conf
input { stdin { } } output { elasticsearch { hosts => [“localhost:9200”] } stdout { codec => rubydebug } }
测试:
/usr/share/logstash/bin/logstash -e ‘input { stdin { } } output { stdout {} }’ –path.settings /etc/logstash
输入:hello world
要将输出直接发送到Elasticsearch(不使用Logstash),请设置Elasticsearch安装位置
如果希望使用Logstash对Filebeat收集的数据执行额外的处理,则需要将Filebeat配置为使用Logstash
通过在Filebeat的输出部分设置选项,可以将Filebeat配置为写入特定的输出。yml配置文件。只能定义一个输出。
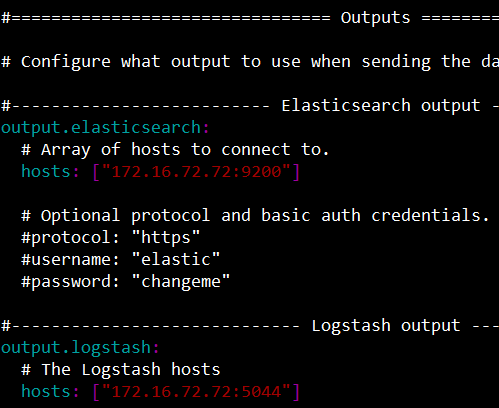
测试定义了 logstash输入
启动 filebeat
/etc/init.d/filebeat start
六、zookeeper 安装及配置(3台)
下载地址:
wget http://mirrors.hust.edu.cn/apache/zookeeper/zookeeper-3.5.6/apache-zookeeper-3.5.6-bin.tar.gz
tar zxvf apache-zookeeper-3.5.6-bin.tar.gz
mv apache-zookeeper-3.5.6-bin /usr/local/zookeeper
编辑配置文件
cd /usr/local/zookeeper/conf
mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
*************************************************
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/data/zookeeper
clientPort=2181
server.72=172.16.72.72:2888:3888
server.75=172.16.72.75:2888:3888
server.88=172.16.72.88:2888:3888
**************************************************
创建myid文件,里面的内容为数字,用于标识主机
mkdir -p /data/zookeeper
echo 72 > /data/zookeeper/myid #配置文件中id标识server.72 75
把zookeeper程序拷贝至其他机器,修改myid并启动服务
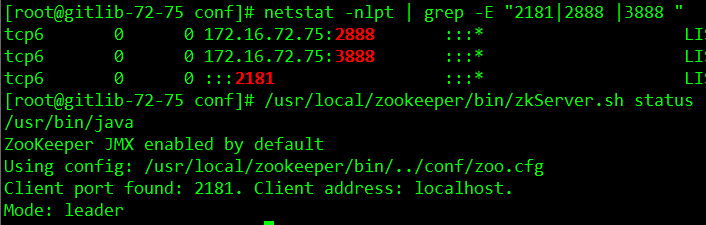
/usr/local/zookeeper/bin/zkServer.sh start
netstat -nlpt | grep -E “2181|2888 |3888 “
查看状态:/usr/local/zookeeper/bin/zkServer.sh status
谁监听了2888 端口,谁就是leader
zoo.cfg配置解释
- tickTime: 用于计算的的时间单元。比如session超时: N*tickTime
- initLimit: 用于集群,允许从单节点连接并同步到master节点的初始化连接时间,以tickTime的倍数来表示
- syncLimit: 用于集群,master主节点与从节点之间发送消息,请求和应答时间长度(心跳机制)
- dataDir: 必须配置
- dataLogDir: 日志目录,如果不配置会与dataLog公用
- clientPort: 连接服务器的端口,默认2181
vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper
export KAFKA_HOME=/usr/local/kafka_2.12-2.3.1
PATH=${ZOOKEEPER_HOME}/bin:${KAFKA_HOME}/bin:$PATH
export PATH
source /etc/profile
连接测试:
/usr/local/zookeeper/bin/zkCli.sh -server 172.16.72.72:2181,172.16.72.75:2181,172.16.16.88:2181
七、kafka安装配置(2台 172.16.72.72、172.16.72.75)
下载:
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.3.1/kafka_2.12-2.3.1.tgz
tar zxvf kafka_2.12-2.3.1.tgz
mv kafka_2.12-2.3.1 /usr/local/
mkdir -p /data/kafka/data
备份并编辑配置文件
vim /usr/local/kafka_2.12-2.3.1/config/server.properties
# Server Basics
broker.id=72
port=9092
host.name=172.16.72.72
advertised.host.name=172.16.72.72
advertised.listeners=PLAINTEXT://172.16.72.72:9092
# Socket Server Settings
producer.type=async
batch.num.messages=100
queue.buffering.max.ms=100
queue.buffering.max.messages=1000
queue.enqueue.timeout.ms=100
queued.max.requests=5000
buffer.memory:335544320
block.on.buffer.full = true
num.io.threads=8
num.network.threads=16
socket.request.max.bytes=104857600
socket.receive.buffer.bytes=1048576
socket.send.buffer.bytes=1048576
fetch.purgatory.purge.interval.requests=100
producer.purgatory.purge.interval.requests=100
# Replication configurations
num.replica.fetchers=4
replica.fetch.max.bytes=5242880
replica.fetch.wait.max.ms=500
replica.high.watermark.checkpoint.interval.ms=5000
replica.socket.timeout.ms=30000
replica.socket.receive.buffer.bytes=65536
replica.lag.time.max.ms=10000
replica.lag.max.messages=4000
controller.socket.timeout.ms=30000
controller.message.queue.size=10
# Log Basics
num.partitions=8
message.max.bytes=5242880
auto.create.topics.enable=true
log.index.interval.bytes=4096
log.index.size.max.bytes=10485760
log.retention.hours=3
log.flush.interval.ms=10000
log.flush.interval.messages=20000
log.flush.scheduler.interval.ms=2000
log.roll.hours=168
log.retention.check.interval.ms=300000
log.segment.bytes=1073741824
log.dirs=/data/kafka/data
delete.topic.enable=true
# Internal Topic Settings
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# Zookeeper
zookeeper.connect=172.16.72.72:2181,172.16.72.75:2181,172.16.16.88:2181/kafka
zookeeper.connection.timeout.ms=6000
zookeeper.sync.time.ms=2000
######## Group Coordinator Settings ##############
group.initial.rebalance.delay.ms=0
启动kafka
nohup /usr/local/kafka_2.12-2.3.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.3.1/config/server.properties > /dev/null &
停止命令:
/usr/local/kafka_2.12-2.3.1/bin/kafka-server-stop.sh
添加centos7启动脚本:(kafka用户启动)测试用root
#vim /etc/systemd/system/kafka.service
[Unit]
Description=kafka
#After=network.target kafka_zk.service
[Service]
WorkingDirectory=/usr/local/kafka_2.12-2.3.1
User=kafka
Group=kafka
ExecStart=/usr/local/kafka_2.12-2.3.1/bin/kafka-server-start.sh /usr/local/kafka_2.12-2.3.1/config/server.properties
TimeoutSec=50
Restart=always
RestartSec=30
StartLimitInterval=30
StartLimitBurst=1
[Install]
WantedBy=multi-user.target
systemctl enable kafka.service
systemctl start kafka.service
systemctl restart kafka.service
修改基础启动脚本
#vim /usr/local//kafka_2.12-2.3.1/bin/kafka-server-start.sh
添加如下内容:
export KAFKA_HEAP_OPTS=”-Xmx4G -Xms4G -XX:PermSize=48m -XX:MaxPermSize=48m -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35″
export JMX_PORT=”9999″
修改日志路径:
# vim /usr/local/kafka_2.12-2.3.1/bin/kafka-run-class.sh
if [ “x$LOG_DIR” = “x” ]; then
#LOG_DIR=”$base_dir/logs”
LOG_DIR=”/data/kafka/logs” #指定新的路径
fi
1)建立一个主题
/usr/local/kafka_2.12-2.3.1/bin/kafka-topics.sh –create –zookeeper localhost:2181/kafka –replication-factor 2 –partitions 1 –topic abc
Created topic abc.
2)查看已创建的主题
cd /usr/local/kafka_2.12-2.3.1
bin/kafka-topics.sh –list –zookeeper 172.16.72.72:2181,172.16.72.75:2181,172.16.16.88:2181 –list abc
3)查看主题详情
cd /usr/local/kafka_2.12-2.3.1
bin/kafka-topics.sh –describe –zookeeper 172.16.72.72:2181 –topic abc
发送消息到abc(ip任意)
bin/kafka-console-producer.sh –broker-list 172.16.72.72:9092,172.16.72.75:9092,172.16.16.88:9092 –topic abc
消费者取消息(ip任意)
bin/kafka-console-consumer.sh –bootstrap-server 172.16.72.72:9092,172,16.72.75:9092,172.16.16.88:9092 –topic abc
bin/kafka-topics.sh –list –bootstrap-server 172.16.72.72:9092
删除topic
bin/kafka-topics.sh –delete –zookeeper 172.16.72.72:2181,172.16.72.75:2181,172.16.16.88:2181 –topic __consumer_offsets
八、kafka集群管理工具kafka-manager部署安装
为了简化开发者和服务工程师维护Kafka集群的工作,yahoo构建了一个叫做Kafka管理器的基于Web工具,叫做 Kafka Manager。这个管理工具可以很容易地发现分布在集群中的哪些topic分布不均匀,或者是分区在整个集群分布不均匀的的情况。它支持管理多个集群、选择副本、副本重新分配以及创建Topic。同时,这个管理工具也是一个非常好的可以快速浏览这个集群的工具,有如下功能:
1.管理多个kafka集群
2.便捷的检查kafka集群状态(topics,brokers,备份分布情况,分区分布情况)
3.选择你要运行的副本
4.基于当前分区状况进行
5.可以选择topic配置并创建topic(0.8.1.1和0.8.2的配置不同)
6.删除topic(只支持0.8.2以上的版本并且要在broker配置中设置delete.topic.enable=true)
7.Topic list会指明哪些topic被删除(在0.8.2以上版本适用)
8.为已存在的topic增加分区
9.为已存在的topic更新配置
10.在多个topic上批量重分区
11.在多个topic上批量重分区(可选partition broker位置)
1. 环境要求
jdk-1.8
kafka集群
72.16.72.72:2181
72.16.72.75:2181
软件:
kafka_2.12-2.3.1
zookeeper-3.5.6
CentOS Linux release 7.7.1908 (Core)
2、下载
https://github.com/yahoo/kafka-manager
从Releases中下载,此处从下面的地址下载 1.3.3.7 版本:
https://github.com/yahoo/kafka-manager/releases
kafka-manager-2.0.0.2.zip
3、修改配置 conf/application.properties
cd /usr/local
unzip kafka-manager-2.0.0.2.zip
cd /usr/local/kafka-manager-2.0.0.2/
./sbt clean dist
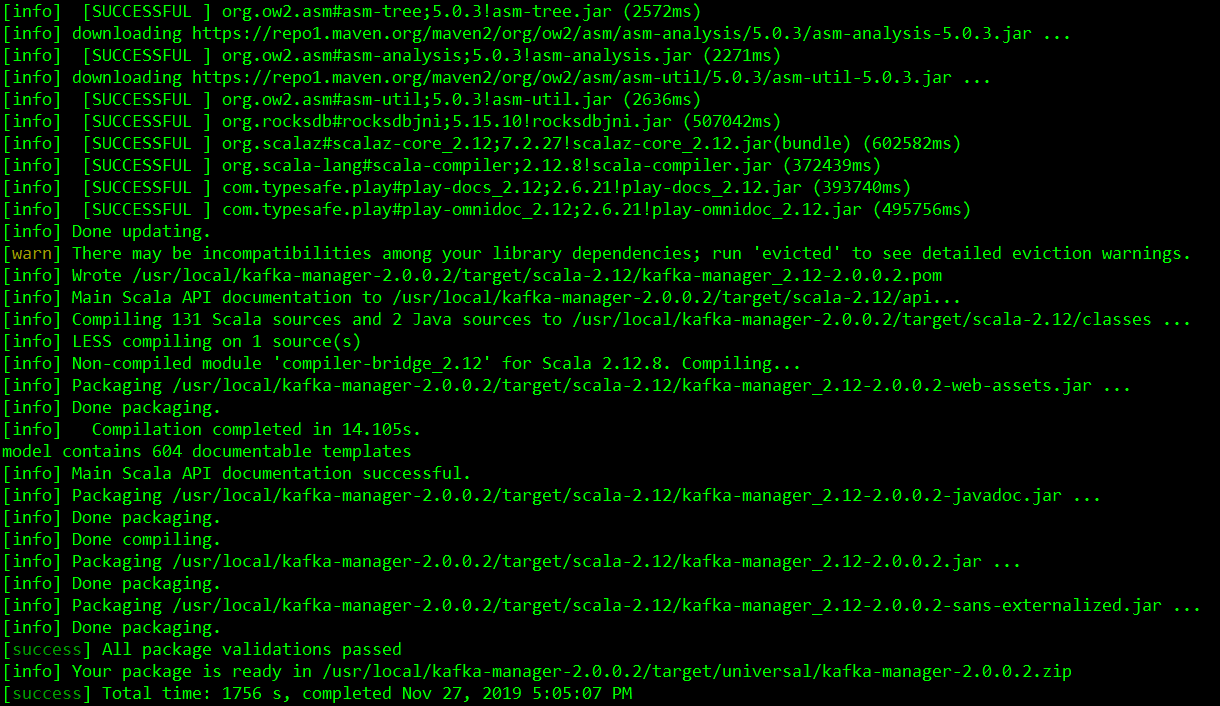
过程比较慢
编译完成后, kafka-manager的解压目录下就会多了一个target文件夹,
cd target/universal/
unzip kafka-manager-2.0.0.2.zip
mv kafka-manager-2.0.0.2 /usr/local/kafka-manager
cd /usr/local/kafka-manager
vim /usr/local/kafka-manager/conf/application.conf
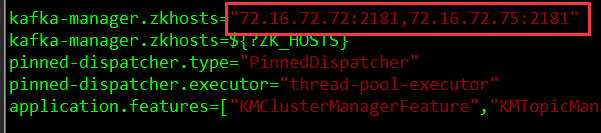
kafka-manager.zkhosts=”kafka-manager-zookeeper:2181″
kafka-manager.zkhosts=”172.16.72.72:2181,172.16.72.75:2181,172.16.16.88:2181″
basicAuthentication.enabled=true
basicAuthentication.enabled=${?KAFKA_MANAGER_AUTH_ENABLED}
basicAuthentication.username=”admin”
basicAuthentication.username=${?KAFKA_MANAGER_USERNAME}
basicAuthentication.password=”admin”
启动
bin/kafka-manager
kafka-manager 默认的端口是9000,可通过 -Dhttp.port,指定端口; -Dconfig.file=conf/application.conf指定配置文件:
nohup bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=9000 &
停止
ps -ef |grep kafka-manager
kill -9 *****
rm -rf /usr/local/kafka-manager/RUNNING_PID
将 kafka-manager.zkhosts 属性修改为您的zk集群地址 将 akka 的loglevel设置为 error ,否则日志文件较多。
——————————————待续

 微信扫一扫,打赏作者吧~
微信扫一扫,打赏作者吧~